https://github.com/Walter0807/MotionBERT
GitHub - Walter0807/MotionBERT: [ICCV 2023] PyTorch Implementation of "MotionBERT: A Unified Perspective on Learning Human Motio
[ICCV 2023] PyTorch Implementation of "MotionBERT: A Unified Perspective on Learning Human Motion Representations" - GitHub - Walter0807/MotionBERT: [ICCV 2023] PyTorch Implementation of ...
github.com
개발 환경
Ubuntu 20.04, CUDA 12.1
Input Video Download
위 링크에서 ‘dancing’ 검색해서 pose estimation에 쓸 동영상을 다운받아 boy.mp4 라는 이름으로 저장하였다.

3D Pose Estimation w.single person
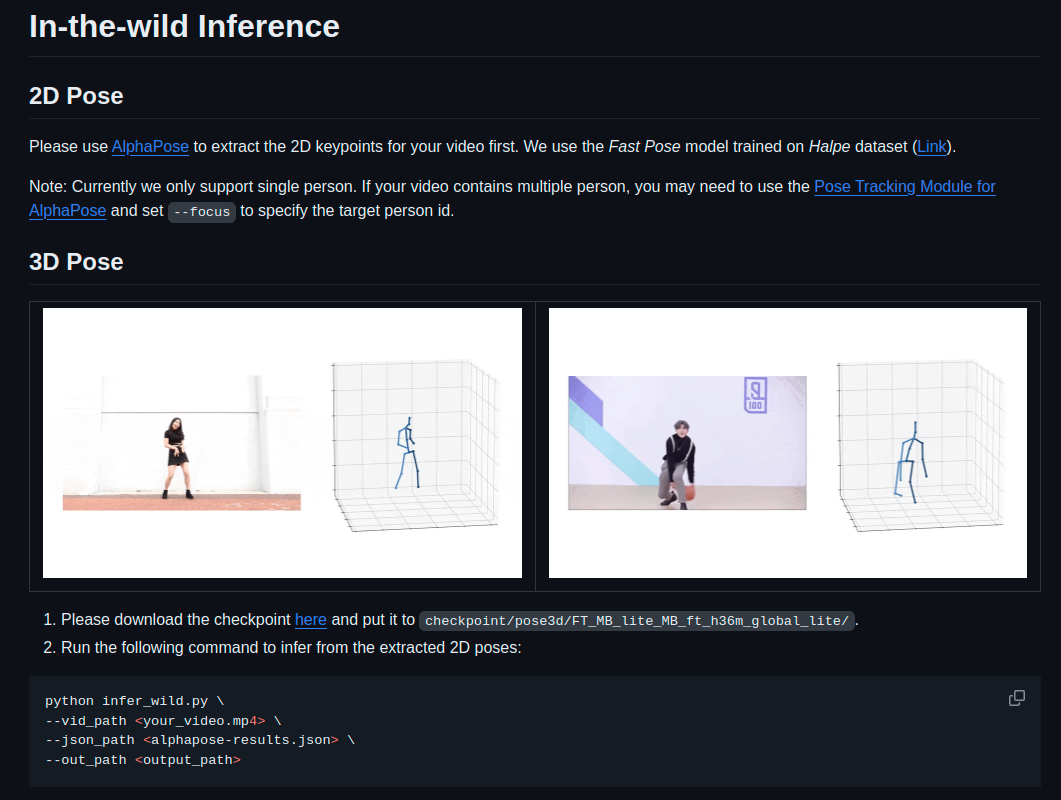
1. 2D Pose w. AlphaPose
MotionBERT를 이용한 3D Pose Estimation을 진행하기 위해서는
AlphaPose를 이용하여 input video의 2D Keypoints를 extract 해야한다.
https://github.com/MVIG-SJTU/AlphaPose
GitHub - MVIG-SJTU/AlphaPose: Real-Time and Accurate Full-Body Multi-Person Pose Estimation&Tracking System
Real-Time and Accurate Full-Body Multi-Person Pose Estimation&Tracking System - GitHub - MVIG-SJTU/AlphaPose: Real-Time and Accurate Full-Body Multi-Person Pose Estimation&Tracking System
github.com
Code Installation
conda create -n alphapose python=3.7 -y
conda activate alphapose
pip3 install torch torchvision torchaudio
git clone https://github.com/MVIG-SJTU/AlphaPose.git
cd AlphaPose
export PATH=/usr/local/cuda/bin/:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64/:$LD_LIBRARY_PATH
python -m pip install cython
sudo apt-get install libyaml-dev
python setup.py build develop
본인은 setup.py 설치가 가상환경에서 잘 안되어서 가상환경 대신 base에서 진행하였다.
Models
- 아래 링크에서 yolov3-spp.weights 설치하고 detector/yolo/data/ 경로에 추가한다. https://drive.google.com/file/d/1D47msNOOiJKvPOXlnpyzdKA3k6E97NTC/view
- 아래 링크에서 Halpe dataset을 이용하여 훈련한 Fast Pose model(halpe26_fast_res50_256x192.pth) 설치하고 pretrained_models/ 경로에 추가한다. https://github.com/MVIG-SJTU/AlphaPose/blob/master/docs/MODEL_ZOO.md
Run
examples/demo/ 경로에 input video(boy.mp4) 추가한다.
python scripts/demo_inference.py --cfg configs/coco/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --video examples/demo/boy.mp4
-> examples/res 경로에 alphapose-results.json 파일 생성이 완료된다.
* Terminal Message (실행 시간 5초)
...
Loading pose model from pretrained_models/halpe26_fast_res50_256x192.pth...
0%| | 0/176 [00:00<?, ?it/s]Loading YOLO model..
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 176/176 [00:05<00:00, 29.58it/s]
===========================> Finish Model Running.
Results have been written to json.
* 마주친 에러들
1. AttributeError: module 'numpy' has no attribute 'float'.
해결: 1.24 이전 버전의 numpy 재설치
pip uninstall numpy
pip install "numpy<1.24"
# numpy-1.23.5 설치 완료
2. AttributeError: 'NoneType' object has no attribute 'shape’
해결: video data 경로를 적을 때, --indir examples/demo/(예시 코드) 대신 --video examples/demo/boy.mp4 사용
2. 3D Pose w. MotionBERT
Code Installation
git clone https://github.com/Walter0807/MotionBERT.git
cd MotionBERT
conda create -n motionbert python=3.7 anaconda
conda activate motionbert
pip3 install torch torchvision torchaudio
pip install -r requirements.txt
Setting
아래 경로에서 checkpoint(best_epoch.bin) 설치하고
checkpoint/pose3d/FT_MB_lite_MB_ft_h36m_global_lite/ 경로 생성하여 추가한다.
https://onedrive.live.com/?authkey=!ALuKCr9wihi87bI&id=A5438CD242871DF0!190&cid=A5438CD242871DF0
Run
vid_path와 json_path는 어디에 있든 상관 없고, 경로 입력만 잘 해주면 된다.
본인은 편의를 위해 data/ 경로에 alphapose-result.json 파일과 boy.mp4 추가해두었다.
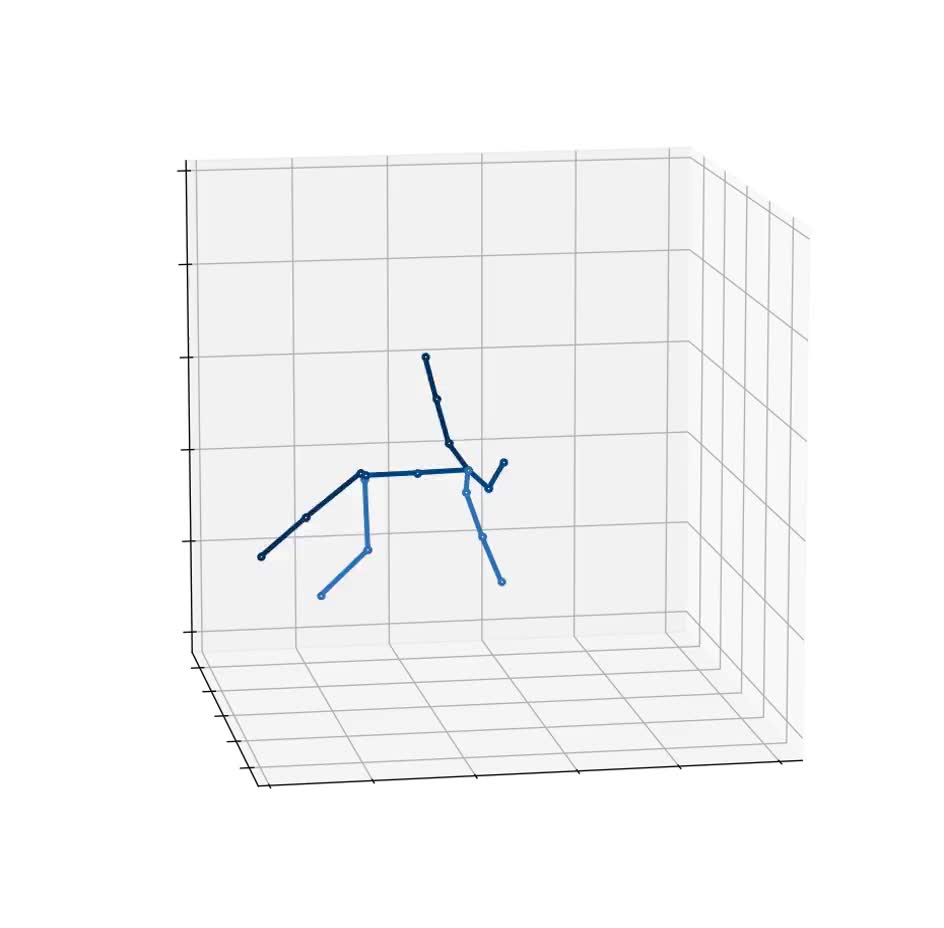
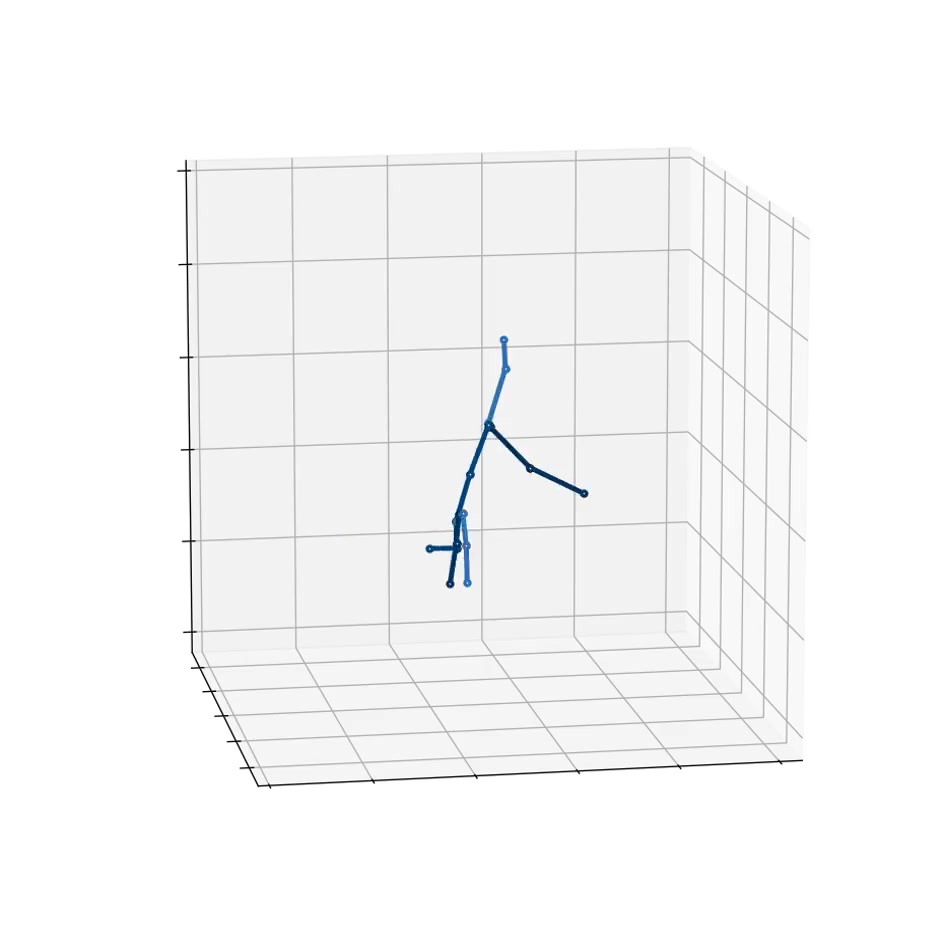
python infer_wild.py --vid_path data/boy.mp4 --json_path data/alphapose-results.json --out_path result
-> result 경로에 X3D.mp4와 X3D.npy 파일 생성 완료
*Terminal Message (실행시간 42초)
Loading checkpoint checkpoint/pose3d/FT_MB_lite_MB_ft_h36m_global_lite/best_epoch.bin
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.58it/s]
0%| | 0/174 [00:00<?, ?it/s]IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (930, 924) to (944, 928) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to 1 (risking incompatibility).
[swscaler @ 0x7230900] Warning: data is not aligned! This can lead to a speed loss
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 174/174 [00:42<00:00, 4.05it/s]
Result (boy.mp4 vs X3D.mp4)


'컴퓨터비전 > 실습' 카테고리의 다른 글
| [컴퓨터비전/실습] YOLOv8을 이용한 Head Detection 간단 실습 (0) | 2024.01.25 |
|---|---|
| [컴퓨터비전/실습] Multi-person Real-time Action Recognition Based-on Human Skeleton을 이용한 버스 승객 탐지 (2) | 2024.01.24 |
| [컴퓨터비전/논문리뷰] Real-time smart lighting control using human motion tracking from depth camera (0) | 2023.12.13 |
| [컴퓨터비전/실습] Instant-NGP with Custom Dataset (0) | 2023.12.13 |
| [컴퓨터비전/실습] Deblurring 딥러닝 기술 비교 (0) | 2023.12.13 |



